
STOCK INSPECTOR: Datos públicos, decisiones privadas, inteligencia competitiva con Python y LLMs

Todo empezó con un problema concreto de un cliente: quería saber cuánto estaba vendiendo su competencia para planificar mejor su stock y negociar con proveedores. Sin esa información, estaba tomando decisiones a ciegas.
Mi primer instinto fue el de siempre: un scraper tradicional en Python, selectores CSS, XPath, BeautifulSoup (lo de toda la vida). Funcionó, hasta que dejó de funcionar.
El problema real del scraping tradicional
Cada vez que una tienda actualizaba su frontend, todo se rompía. Un cambio de clase CSS y la lógica dejaba de funcionar. No era un bug mío, era el problema fundamental del enfoque: estaba acoplando mi código a la estructura visual de sitios que no controlo y que cambian sin previo aviso.
Necesitaba algo que entendiera una página como lo haría una persona, sin importar cómo estuviera construida.
STOCK INSPECTOR trabaja exclusivamente con datos públicos. Todo lo que la herramienta analiza es exactamente lo que cualquier consumidor ve al navegar una tienda online: precios visibles, disponibilidad de productos y niveles de stock publicados.
No accede a bases de datos privadas, no extrae información de usuarios, ni interactua con sistemas internos de ninguna tienda.
Es el equivalente digital de recorrer tiendas anotando precios, pero automatizado y a escala.
El cambio de enfoque: delegar la extracción a un LLM
Integré Gemini API para que sea el modelo quien interprete el contenido público de cada página e identifique productos, precios y disponibilidad en lenguaje natural. Sin selectores rígidos, sin mantenimiento constante ante cambios de diseño.
El momento que cambió todo fue cuando le pasé el contenido de una página que había destrozado tres versiones anteriores de mi scraper, y Gemini extrajo correctamente cada producto con su precio y estado de stock.
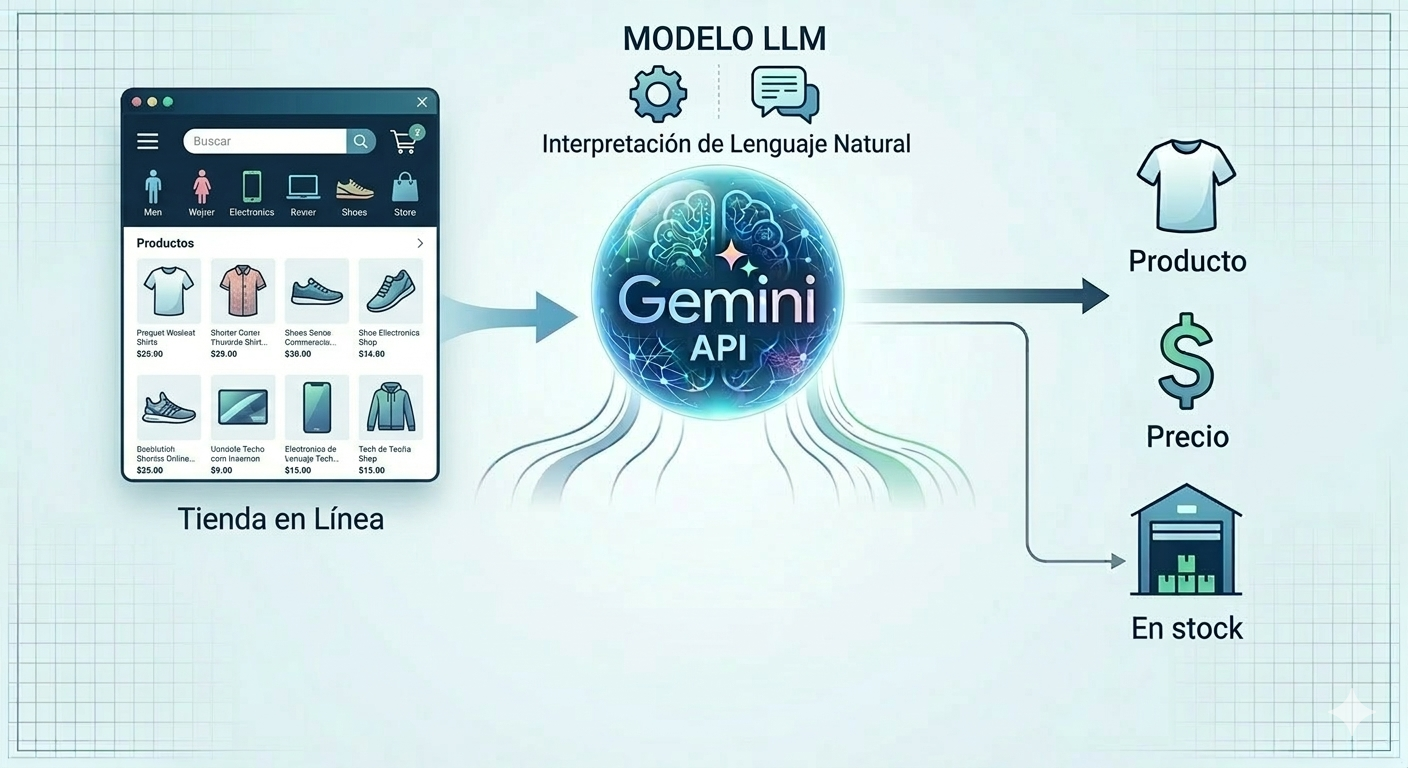
Ahí entendí que había cambiado de paradigma: de extraer estructura a comprender contenido.
La lógica de estimación de ventas
Una vez resuelto el problema de extracción, vino el verdadero valor para el cliente. El pipeline en cada ejecución captura el stock público de cada producto en cada tienda monitoreada. La lógica es simple pero efectiva:
Stock de ayer - Stock de hoy = Ventas estimadas del día
Si el stock bajó, alguien compró. Esa delta acumulada en el tiempo genera una aproximación del volumen de ventas por producto y por tienda, construida enteramente sobre información que las propias tiendas publican abiertamente.
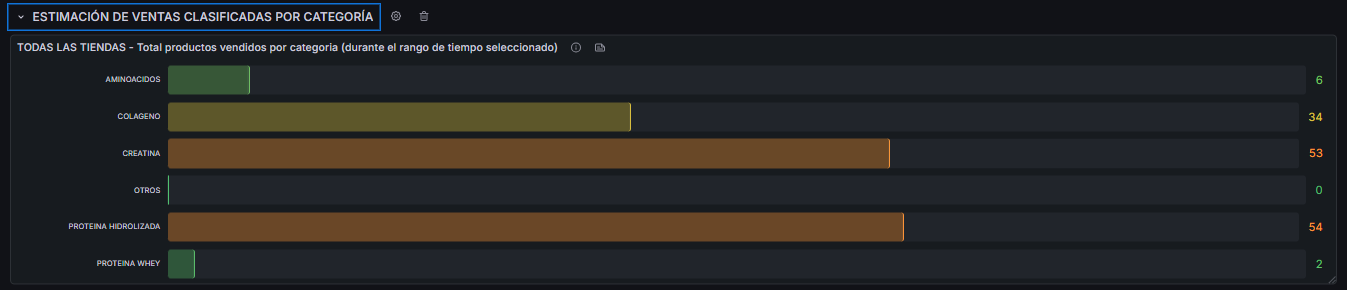
Con esa información el cliente puede estimar qué productos se mueven más rápido en la competencia, cuándo recargan inventario, y usar eso como argumento concreto en sus negociaciones con proveedores. Pasa de negociar con intuición a negociar con datos.
Las decisiones técnicas detrás del stack
Gemini API para extracción inteligente. Elegí Gemini sobre otras opciones por una razón práctica: su consola de Google AI Studio ofrece visibilidad clara sobre el uso de la API, costos, errores y transacciones en tiempo real. Para un proyecto productivo con un cliente real, necesitaba saber exactamente qué estaba consumiendo, cuánto me costaba y dónde fallaba. Esa transparencia operacional fue determinante en la decisión, además de su capacidad para interpretar contenido web en lenguaje natural, eliminando la fragilidad del scraping tradicional basado en selectores.
Docker para portabilidad. Contenerizar desde el inicio me permite correr el sistema igual en cualquier entorno sin depender de configuraciones locales ni sorpresas en producción.
Hostinger + Easypanel en lugar de un cloud grande y Kubernetes. Soy honesto sobre esto: no necesitaba la complejidad operacional de AWS, GCP o Azure, ni la de Kubernetes para este proyecto. Me decidí por Hostinger porque me da un servidor con costo fijo y predecible, sin sorpresas en la factura de fin de mes. Encima de eso, Easypanel resuelve todo lo que necesito: despliegue de contenedores, gestión de variables de entorno y logs, sin overhead innecesario. Para un proyecto personal con un cliente real, mantener los costos controlados es tan importante como la arquitectura técnica. Es una decisión que repetiría de ser necesario.
Prometheus y Grafana para observabilidad de negocio. Esta fue una decisión de arquitectura desde el inicio, no un añadido posterior. En lugar de construir dashboards desde cero, elegí dos herramientas open source ampliamente adoptadas y probadas en producción que tienen toda la infraestructura de visualización resuelta. Prometheus exporta métricas de stock y estimaciones de ventas, y Grafana las expone en dashboards siempre disponibles para el cliente; esa decisión me ahorró semanas de desarrollo y me permitió enfocarme en la lógica de negocio en lugar de en la capa de presentación.
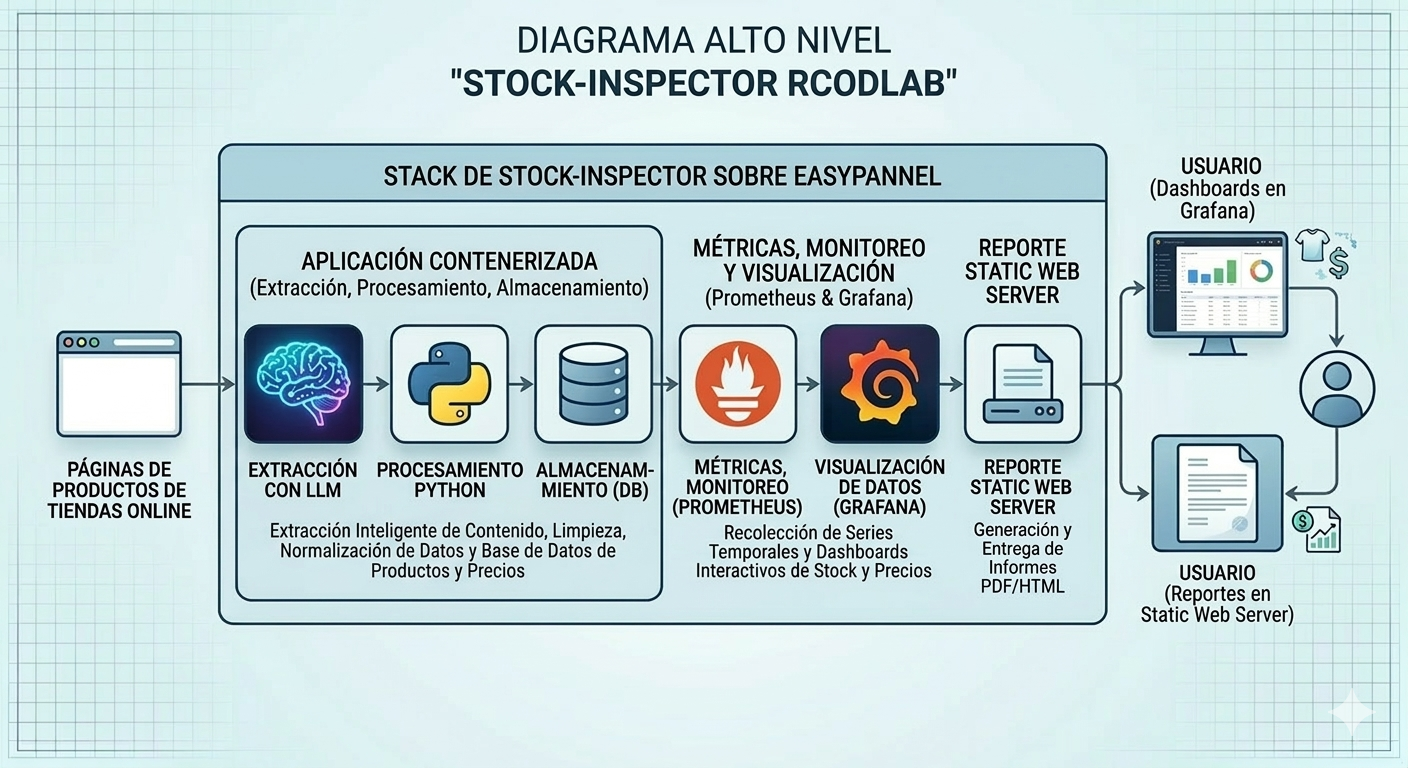
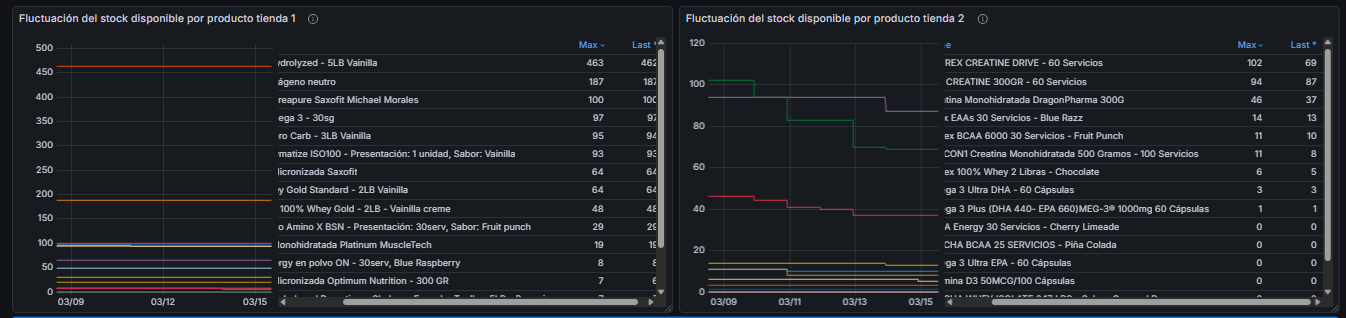
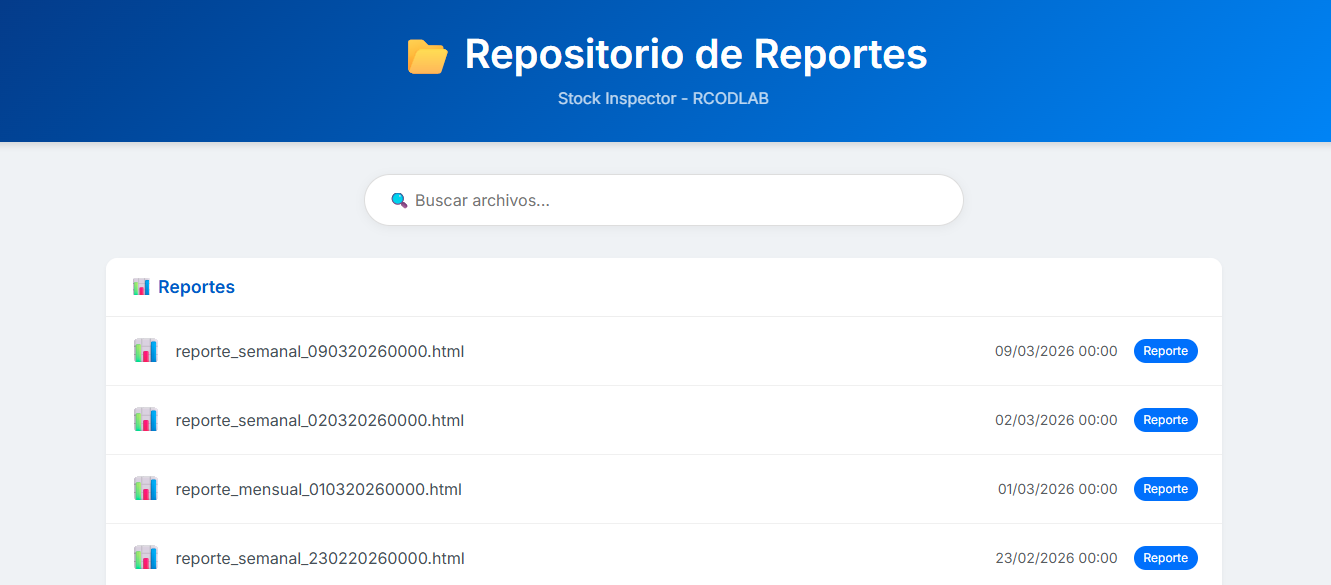
Cómo recibe el cliente la información
El cliente accede a dos cosas: una página estática con reportes semanales y mensuales de ventas estimadas por producto y competidor, y un dashboard en Grafana donde puede ver la fluctuación de stock y precios en tiempo real. No necesita entender nada técnico, solo interpretar las gráficas y tomar decisiones comerciales con respaldo de datos.
Lo que haría diferente
Honestamente, poco. Las decisiones técnicas centrales funcionaron desde el inicio porque partieron de un razonamiento claro: usar herramientas probadas en lugar de reinventar la rueda.
Lo que sí haría diferente es documentar mejor las decisiones técnicas desde el inicio, precisamente para poder contarlas con más detalle después. Este post me costó más de lo que debería porque tuve que reconstruir el razonamiento detrás de cada decisión de memoria.
¿Qué sigue?
Estoy explorando LangChain para que el cliente pueda hacer preguntas sobre sus datos en lenguaje natural, en lugar de solo consultar reportes estáticos. La idea es que pueda preguntar cosas como ¿qué producto de la competencia tuvo mayor caída de stock esta semana? y obtener una respuesta directa conversacional.
STOCK INSPECTOR es el primer producto bajo mi marca personal RCODLAB, donde construyo herramientas que combinan Python, LLMs y observabilidad para resolver problemas reales de negocio.
Si estás construyendo algo similar, tienes preguntas sobre el stack, o simplemente quieres conversar sobre inteligencia competitiva con datos públicos, con gusto hablamos.
Discusión de miembros